Introduction
Cloud HPC can help speed up the procurement process and provide flexibility that on-premises HPC cannot offer.
However, this does not mean that taking time to design, iterate, and engage with key members of your organisation can be skirted around.
One key area that can often be overlooked is monitoring. Monitoring can provide a Cloud HPC service with a wealth of data that can be used to optimise cost, performance, and maintain service health.
Most importantly, the optimisation of any HPC service must be supported by evidence to ensure that performance, user experience and requirements are not compromised.
Cloud providers offer a variety of tools for monitoring as part of the package of using their services, e.g. Azure Monitor, Amazon Cloud Watch, GCP Cloud Monitor and many others.
In this article, I am going to look at the importance of monitoring and the tools to do it.
Where to Start?
 Ideally, conversations and requirement definitions with respect to monitoring are happening towards the start of a project and are considered alongside the wider design of the system.
Ideally, conversations and requirement definitions with respect to monitoring are happening towards the start of a project and are considered alongside the wider design of the system.
However, it is not a major problem if monitoring is late to the party, as it is generally unobstructive to other system services, but may require downtime to put in place.
Nevertheless, no matter what stage you consider monitoring, it is crucial to answer some questions about the solution:
What data do we need?
a. Are there any KPIs we need to measure?
b. Do we have crucial services that need a greater level of monitoring than others?
c. Which machines need monitoring?
d. Are you monitoring the same data points on all machines or is it tailored?
e. Are the capabilities of the cloud providers monitoring solution sufficient or do you need custom tools?
f. How real-time does the data need to be?
Is there a performance impact from monitoring?
a. Are cycles being taken away from computation?
Where does the data live after being gathered? (If it’s on the machine it was gathered from, consider the risk of that machine being lost!)
a. Database software and structure?
b. The cost of storing the data?
c. Who needs to access the data post-collection?
Who is the target audience for the data?
a. Administrators? Business leaders? Users?
b. How do we visualise the data? Dashboards? Regular reports?
What alerts are needed?
a. Identify crucial services.
b. Basic system data e.g. CPU, disk usage, Memory, interconnect?
No one knows your organisation as well as you do and there may be different questions that need answering once you start exploring the topic.
The key is that considering these points early on in a project allows a clear set of requirements for the monitoring service to be established.
Available Tools
Building monitoring into your design makes cost optimisation of your cloud consumption easier down the road.
The cloud offers two main categories of tools to help you monitor your consumption:
- Governance and organisation tools.
- Usage, health, and performance monitoring tools.
Governance and organisational tools assist a business with separating resources, policies and costs between their different departments, regions etc.
Moving IT to the Cloud has helped businesses to have better oversight of their overall IT estate.
This is a major plus however, it can lead to roadblocks when deploying a Cloud HPC. My colleague Manveer talks about this in his blog on Tips for Cloud Deployment.
Governance and Organisation Tools
Using tools such as subscriptions, accounts, organisations, management groups, blueprints etc are the first steps in creating a successful Cloud HPC service.
Organising your Cloud resources into structures based on their intended service or function allows you to use these as filters later when looking at usage and ultimately the cost of those services.
Policies and budgets are incredibly powerful tools on the cloud and allow a central authority to enforce rules, guidelines, and limits from the beginning of any deployment.
For example, an organisation may want to restrict the VM types available to provide a crude form of cost control and stop new projects from using expensive VMs without extra authorisation.
Usage Monitoring
Once a structure for your resources is in place and you start deploying them, the next phase is about monitoring their cost, health, and performance.
Tools available from cloud vendors often provide data about the cost of resources and their health and performance.
Looking at usage data will allow you to see trends and identify anomalies as early as possible. A stacked column chart is particularly useful for seeing general trends in usage.
The example below shows some data from an Azure subscription showing a rapid drop in spending on Virtual machines (light blue) in October.
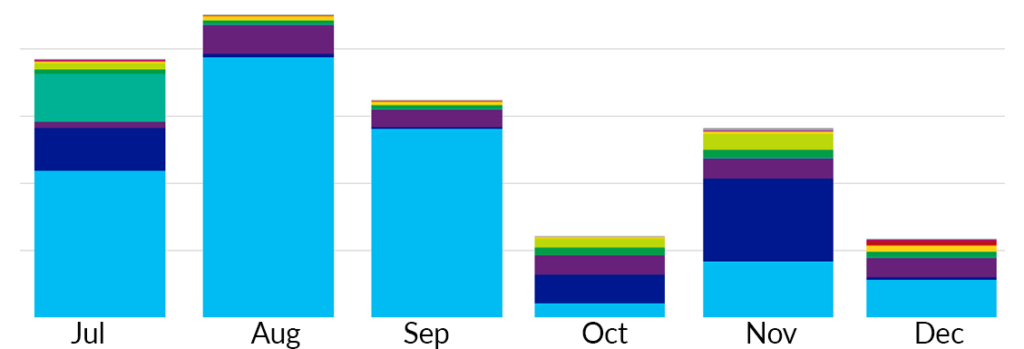
Viewing the high-level cost data in this format allows an administrator
to quickly spot any unexpected changes.
In addition, a cost optimisation exercise in the following September can use this data to focus on the areas with the potential for the biggest savings first e.g.
by optimising VM usage using automatic on/off schedules or deleting stray resources that have not been cleaned up from an old project.
These tools provide the ability to drill down from a top-level account down to a single resource and are perfect for creating a dashboard.
 Health and Performance Monitoring
Health and Performance Monitoring
Monitoring of performance and service health is also crucial. Most Cloud vendors offer basic data on this such as CPU usage, memory usage, and uptime.
However, they do not by default provide details such as services running on the machines, user logins, or e-data from system/application logs.
With sufficient preparation, these can also be monitored.
System/Application logs on Virtual machines can be extracted and fed into cloud services such as Log Analytics on Microsoft Azure.
Another approach is using some of the most popular monitoring tools such as Prometheus + Grafana. While these are powerful tools and provide a lot of data by default, they may not be appropriate or approved for use within your organisation.
The exact approach taken to monitoring the system is less important than the fact that it is being monitored.
Health and performance data is best used to create alerts to identify issues before they become issues.
Using the data!

With all your data collected, it is important to make it as accessible as possible. A common way of doing this is to create a dashboard.
Cloud vendors typically have a dashboard tool that will let you pre-define charts and metrics and organise them into a dashboard.
These tools are extremely useful for making data accessible to all who need it since they are readily available through the cloud portal via the web browser.
If you need more advanced dashboarding capabilities, tools such as Grafana and PowerBI are industry favourites.
The choice of tool is not as important as the clarity of data on the dashboard. To achieve this, it may be better to create multiple dashboards based on who is viewing rather than trying to cram everything into one.
A system administrator needs quite different information from a business leader or user of the service.
Conclusion
A Cloud HPC system that is not monitored can be very costly and is likely to malfunction without notice.
When thinking about monitoring, it helps to consider how your business would function if your system went offline.
Well-designed monitoring systems are the first sirens when a major issue is either about to happen or has just happened and are crucial for a timely support response.
Constant performance, health, and usage data monitoring can provide a feedback loop that can be used to constantly optimise your cloud HPC usage and to alert you to or prevent issues.
One of the best ways to do this is on a dashboard using built-in tools from your cloud provider or other popular tools such as Grafana.
With data that is collected and refined into a dashboard, an HPC service can assess its level of service with ease and provide an improved user experience for all.
We can help you design, implement, and actively support your cluster and its monitoring needs with Red Oak Consulting and Red Oak Managed Services.
 JAMES PAGE
JAMES PAGE
